Imagine two people controlling the same light.
One person switches it off because the room is empty. Two seconds later, the other switches it back on because the rule says the light must always be on. Neither person is ignoring instructions. The problem is that their instructions conflict.
That is roughly what happened to one of our production services.
Every six minutes, Kubernetes removed the running service and created a new one. From the application logs, it looked like the service was crashing repeatedly. But the application was not crashing. Two automated systems were fighting over how many copies of it should be running.
This is the story of how we found that conflict, fixed the immediate problem, and changed our deployment process so the same gap would not return later.
A few terms before we continue
You do not need deep infrastructure experience to follow this story, but these terms will help:
- Kubernetes runs applications across servers and tries to keep them in the state we ask for.
- A pod is one running copy of an application.
- A replica is another word for a running copy. One replica means one pod; three replicas means three copies are available to serve requests.
- A controller is an automated manager. It watches the system and makes changes when reality differs from its instructions.
- KEDA is an autoscaler. It can add application copies when demand rises and remove them when demand falls.
- ArgoCD is a deployment controller. It compares the live system with the configuration stored in Git and corrects differences.
- GitOps is the practice of treating configuration in Git as the source of truth for what should be running.
KEDA and ArgoCD were both useful. The failure came from giving them authority over the same setting without making their responsibilities clear.
The two conflicting instructions
The service was configured to scale down to zero when nobody was using it:
KEDA: when the service is idle, run 0 copiesThe deployment configuration still said:
ArgoCD: the desired configuration says run 1 copyBoth systems acted correctly.
- KEDA waited through its idle period and changed the number of replicas from one to zero.
- Kubernetes removed the pod.
- ArgoCD saw that production no longer matched the configuration declaring one replica.
- ArgoCD’s self-healing feature changed the number back to one.
- Kubernetes created a new pod.
- A few minutes later, KEDA scaled it back to zero and the cycle began again.
1 running pod
↓
service remains idle
↓
KEDA scales 1 → 0
↓
pod is removed
↓
ArgoCD restores 0 → 1
↓
a new pod starts
↓
repeat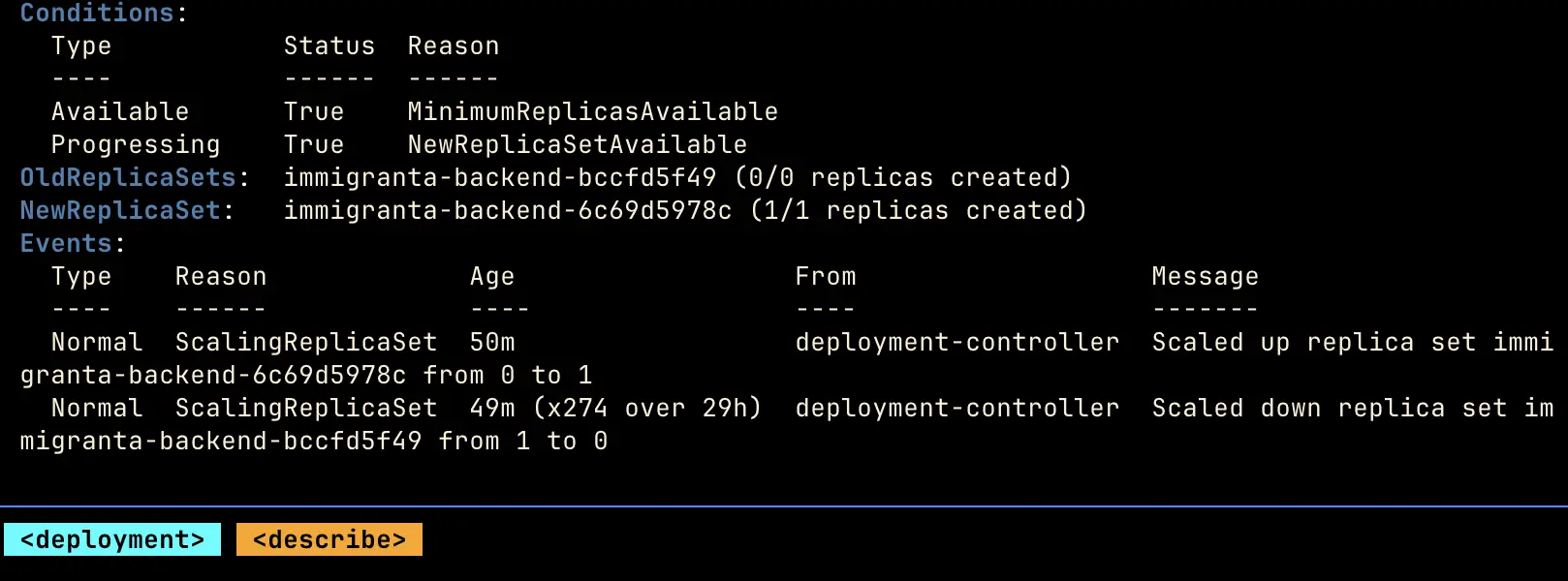
K9s showing the deployment events behind the loop: one replica set scaled up from zero to one while the previous replica set repeatedly scaled down from one to zero.
The service appeared to reboot on a regular schedule because that was effectively what the two controllers had built together: a loop.
Why scale to zero at all?
Some applications receive traffic constantly. Others spend long periods idle. Keeping an unused application running still consumes memory and computing capacity.
KEDA can watch demand and adjust the number of copies automatically:
httpScaledObject:
targetConcurrency: 15
minReplicas: 0
maxReplicas: 3In plain English:
- Aim for no more than 15 active requests per application copy.
- Run no copies when the service is completely idle.
- Run up to three copies when demand increases.
This service often waits for an AI model, an embedding provider, or a database. CPU usage alone does not show how busy it is, so we scaled it using the number of requests currently in progress.
Scale-to-zero was an intentional cost-saving experiment. The mistake was not the idea itself. The mistake was enabling it without confirming that ArgoCD would leave the replica count under the autoscaler’s control.
The confusing part: the correct fix was already in Git
The repository contained a rule telling ArgoCD to ignore changes to the replica count:
ignoreDifferences:
- group: apps
kind: Deployment
jsonPointers:
- /spec/replicasThat rule means:
The application autoscaler owns the number of running copies. Do not treat its changes as unwanted configuration drift.
So why did ArgoCD still fight KEDA?
Because the rule existed in Git but not in the live ArgoCD configuration.
That sounds impossible if Git is the source of truth, but our GitOps setup had a boundary:
ArgoCD Application
↓
Helm chart and environment values
↓
production resourcesThe ArgoCD Application is the object that tells ArgoCD which repository,
configuration, and cluster to use. ArgoCD continuously updated everything below
that object.
But the Application object itself had been installed manually with
kubectl apply. Nothing above it was watching for later changes.
This meant:
- The KEDA change reached production because it lived inside the configuration ArgoCD already watched.
- The
ignoreDifferencesrule did not reach production because it changed the ArgoCDApplicationitself.
Git contained one complete, correct change. Production received only half of it.
How we knew it was not a crash
The application logs showed a clean startup every six minutes, followed by silence. There were no error messages or normal shutdown messages.
That initially looked like the process was being killed. The deciding evidence was in Kubernetes:
Restart Count: 0If the application had crashed and restarted inside the same pod, that count would have increased.
Instead, every cycle had a new pod name and a restart count of zero. Kubernetes was not restarting a failed container. It was deleting one pod and creating another because the requested replica count kept changing.
The deployment events confirmed the sequence:
Scaled down ... from 1 to 0
Scaled up ... from 0 to 1That distinction changed the investigation:
Repeated application boots
≠ automatically a crashing application
New pod names + Restart Count: 0
= the platform is replacing or rescaling podsThe three changes we made
The incident led to three separate actions. They solved different problems.
1. Apply the missing ArgoCD rule
We updated the live ArgoCD Application so it contained the same
ignoreDifferences rule as Git.
That corrected the stale configuration and stopped ArgoCD from treating normal autoscaler activity as something it needed to undo.
2. Keep one warm production replica for go-live
We also changed production from:
minReplicas: 0to:
minReplicas: 1This was part of preparing the product for public go-live, not the fundamental fix for the controller conflict.
A public API is monitored continuously and should respond without waiting for a cold start. Keeping one replica warm means one copy is always ready, while KEDA can still increase the service to two or three copies when traffic rises.
Ideally, we would have set the production minimum to one from the beginning. Scale-to-zero can still make sense for development environments, background tools, or services where a delayed first request is acceptable. It was not the right default for this monitored, user-facing production API as we approached go-live.
3. Create an app-of-apps
The most important post-incident change was structural.
We created a parent ArgoCD application called root-prod. Its job is to watch
and deploy the production ArgoCD Application objects themselves.
The reconciliation chain now begins one level higher:
root-prod
↓
production service Applications
↓
Helm charts and environment values
↓
production resourcesThis pattern is commonly called app-of-apps: one parent application manages the applications below it.
Before root-prod, changing a service’s ArgoCD Application still depended on
someone remembering to run kubectl apply. Now a merged Git change can update
that object through ArgoCD as well.
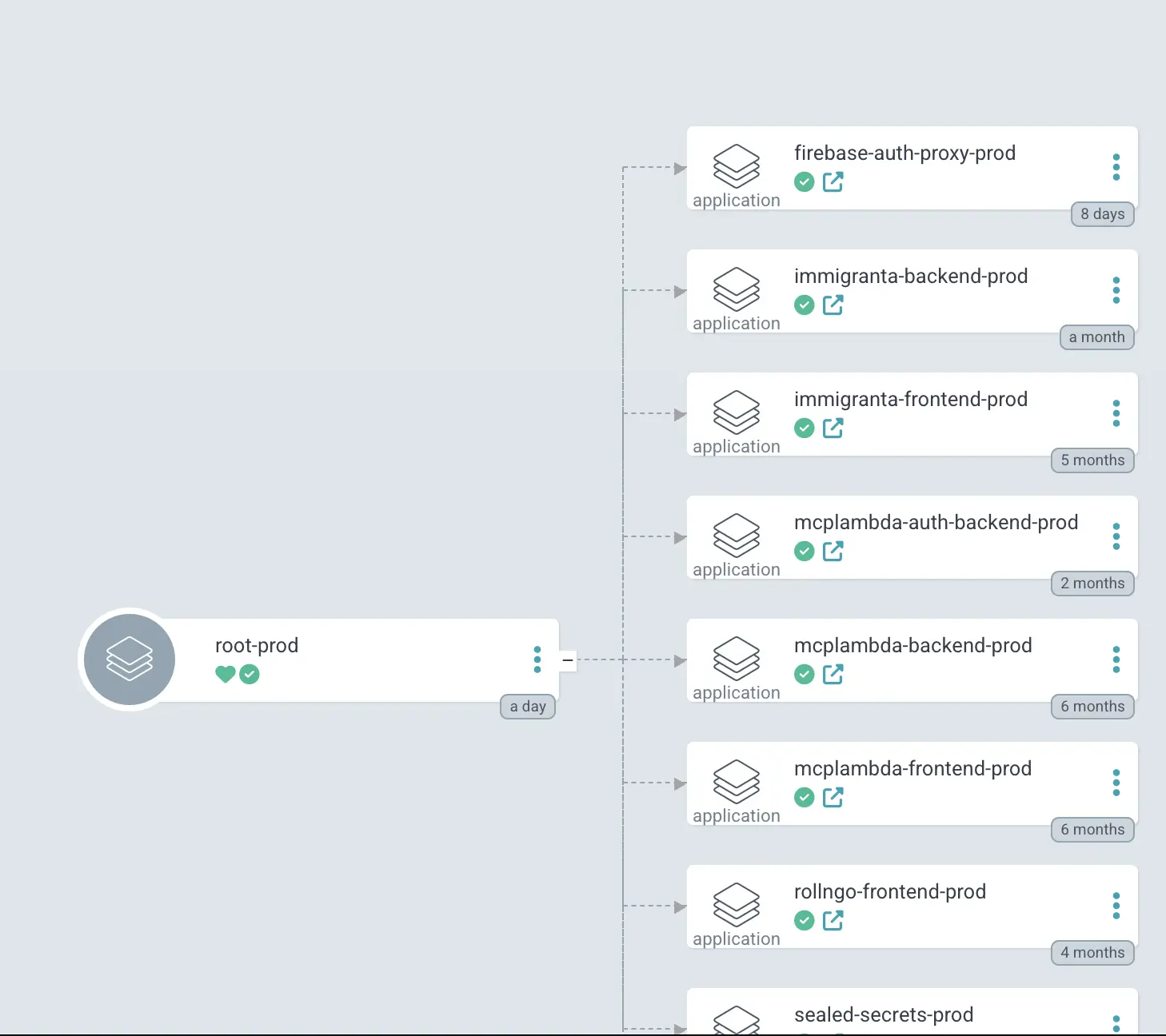
The root-prod app-of-apps now manages the production service applications,
including immigranta-backend-prod.
The immediate fix corrected one stale object. The app-of-apps change removed the manual gap that allowed it to become stale.
Notes for future me
These are the checks I want to remember when a Kubernetes service appears to restart repeatedly:
- Check whether the pod name stays the same.
- Check the container restart count.
- Check recent scaling and deployment events.
- Compare memory usage with the configured limit.
- List every controller that can change the disputed field.
- Compare the live ArgoCD
Applicationwith the version in Git. - Trace the GitOps chain upward: what deploys the
Applicationitself?
Useful commands:
# Pod names and restart counts
kubectl get pods -n prod \
-l app=immigranta-backend \
-o custom-columns='NAME:.metadata.name,RESTARTS:.status.containerStatuses[0].restartCount'
# Recent scaling and replacement events
kubectl get events -n prod \
--sort-by='.metadata.creationTimestamp' \
| grep -iE 'immigranta|scaled|killing|unhealthy|oom'
# Memory usage
kubectl top pod -n prod -l app=immigranta-backend
# The managers that have written deployment fields
kubectl get deploy immigranta-backend -n prod \
-o yaml \
--show-managed-fields
# or better still, use k9sOne extra ArgoCD detail to remember: ignoreDifferences controls how ArgoCD
compares desired and live state. If ArgoCD must also omit that field during
every sync, investigate the RespectIgnoreDifferences=true sync option and test
the behavior against the installed ArgoCD version.
What I am carrying forward
Automation is most reliable when ownership is explicit.
KEDA should own the live replica count. ArgoCD should deploy the application without reversing legitimate autoscaling decisions. And the parent app-of-apps should ensure that changes to ArgoCD’s own instructions also reach the cluster.
Nothing here failed because Kubernetes ignored us. The opposite happened: every controller followed the instructions it had been given. The system failed because those instructions disagreed and one of the corrections existed only in Git.
That is why the post-mortem could not end with restarting a pod or applying one missing file. We had to close the gap that made the live configuration drift from the repository in the first place.
This article focuses on that infrastructure lesson. In the next article, I will share the fuller post-mortem: the production alert that started on my phone, the two convincing diagnoses that turned out to be wrong, the evidence that changed the investigation, and how a supposed application crashloop led us all the way back to the design of our GitOps system.
Comments